Allô Montréal
Published at Aug 23, 2024
View live: allo-montreal
Source: allo-montreal
This entry is about choroplets and how Observable Framework facilitate streamlining the data pipeline.
Choroplet maps are fun. People love them. The earliest known choroplet was by Charles Dupin in 1826. He called them “cartes teintées, which I think is a better name. Here is my early prototype of Montreal, with counties tinted by population size:
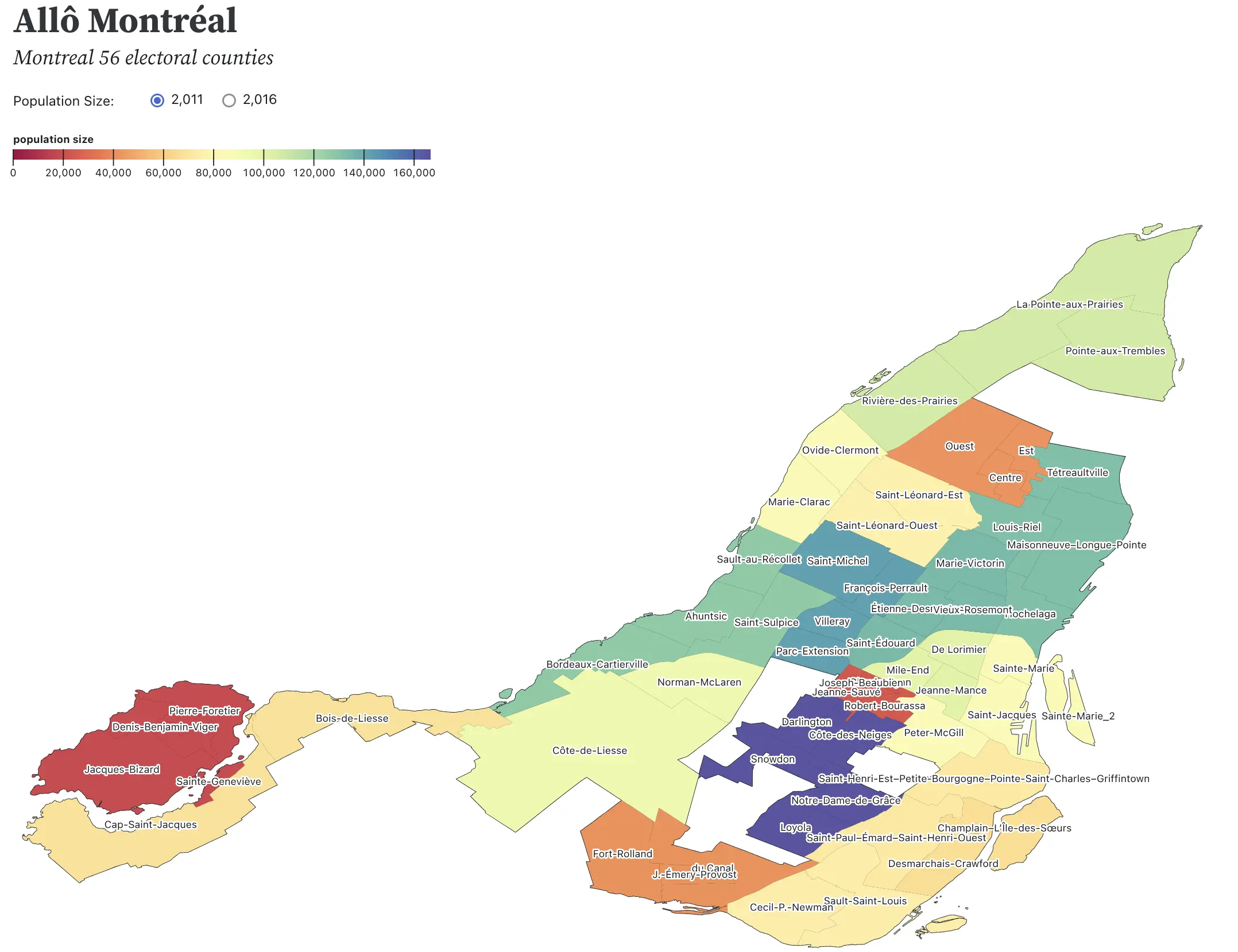
Are they useful? It depends on how you use them. They represent one variable overlayed on a map. If we understand that variable as a predictor, it will almost always be confounded by other ones. A classic example is that of age-standardized death rates for cancer of kidney/ureter in the US. If you look at both the highest and lowest death rates, you will notice that the maps are extremly similar (see Gelman & Nolan 2009 p.14-15). This is because kidney/ureter cancer deaht rates are confounded by population size of urban centers.
Anyway, we love choroplet maps. You still can get insights by looking at them. For instance, I never realized how sparsely populated was Outremont in Montreal (dark red in the middle of the city, Outremont includes Joseph-Beaubien, Robert-Bourassa, Jeanne-Sauvé, and Claude-Ryan electoral counties). I guess it make sense, it is an historically rich district. Same with the city of Westmont.
Now, I want to talk about why Observable Framework is awesome. One issue with dashboard is that they end up rotting.In my experience, one reason why dashboards rot is that we fail to properly document the data pipeline. Following a principled data pipeline, here data provenance is documented by the scripts themselves. If you look at the source code, you will notice there are no data files. The data is loaded at build-time by the data loaders (metadata.parquet.py and mtl_topo.json.py).
It is awesome because we (i) keep using a little bit more python for data wrangling, (ii) we document where the data is coming from by having the links in the script, and (iii) we output as parquet file. As documented here, our python environment is specified by a requirements.txt file in our root dir (and create with venv), that is run before deployment.