PDF-zoo
Published at Oct 10, 2024
View live: pdf-zoo
Source: pdf-zoo
How do you know when you have decent text extraction from PDFs? In my experience, you know when you know. To some degree, we can say that tool A is better than B is it correctly convert text embedded in PDF in text files. But most often determining the quality of text extraction also depend on the specific problem at hand. Like with Large Language Models (LLMs), one of the best ways to assess the quality of text extraction tools is to have people vote on them (see the Chatbot Arena LLM Leaderboard). I built a small data app that, while it doesn’t let you vote just yet, at least allows you to compare the outputs of various popular text extraction tools.
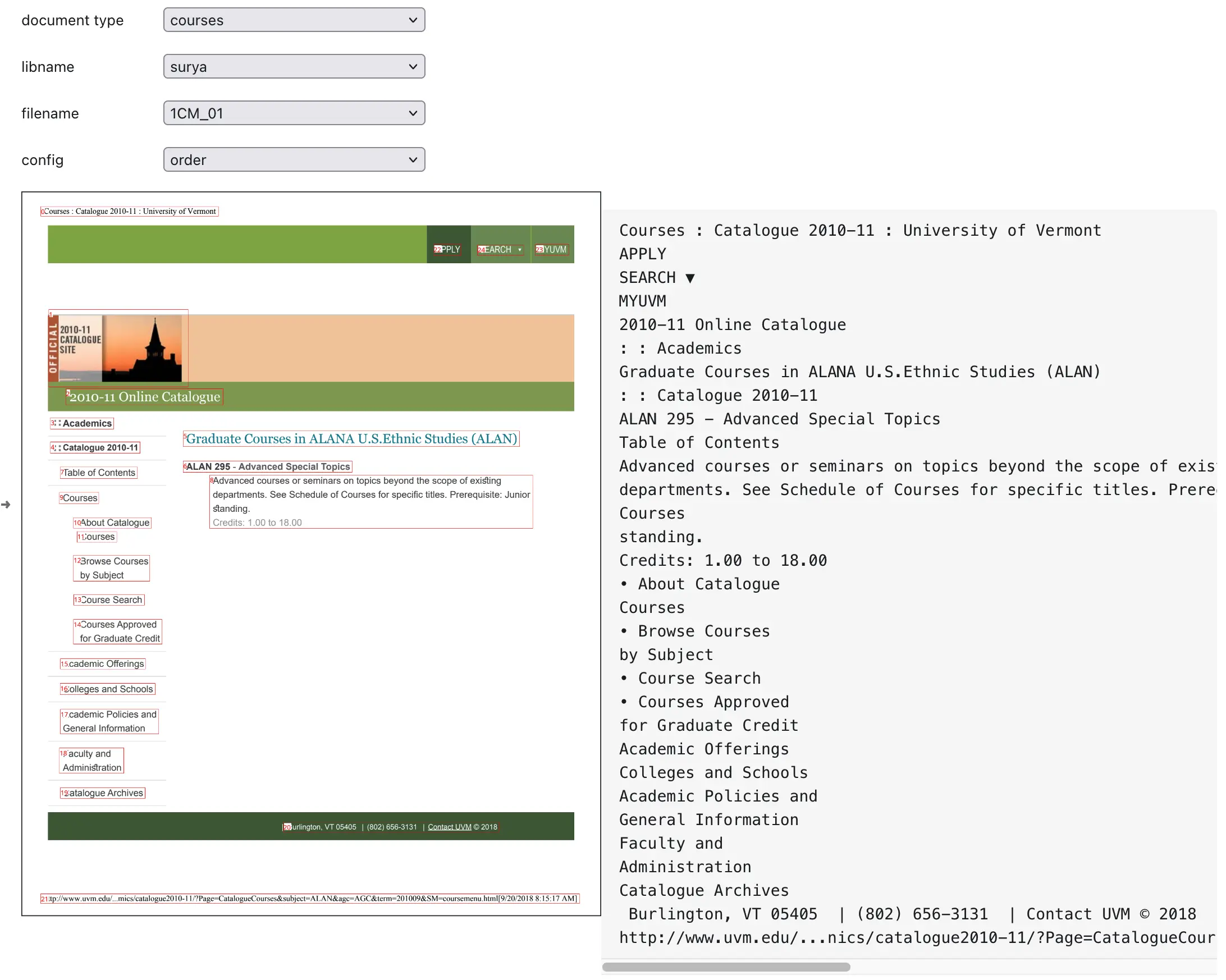
On the left, you see what the tool sees. In recent years, the community has realized that converting PDFs to text requires an understanding of the document’s spatial organization—you need to grasp how the different parts of the text fit together. On the right, you can see the extracted text and the quality of that extraction. Some tools now even output markdown, which goes beyond just the text by capturing the role of the text within the document itself.
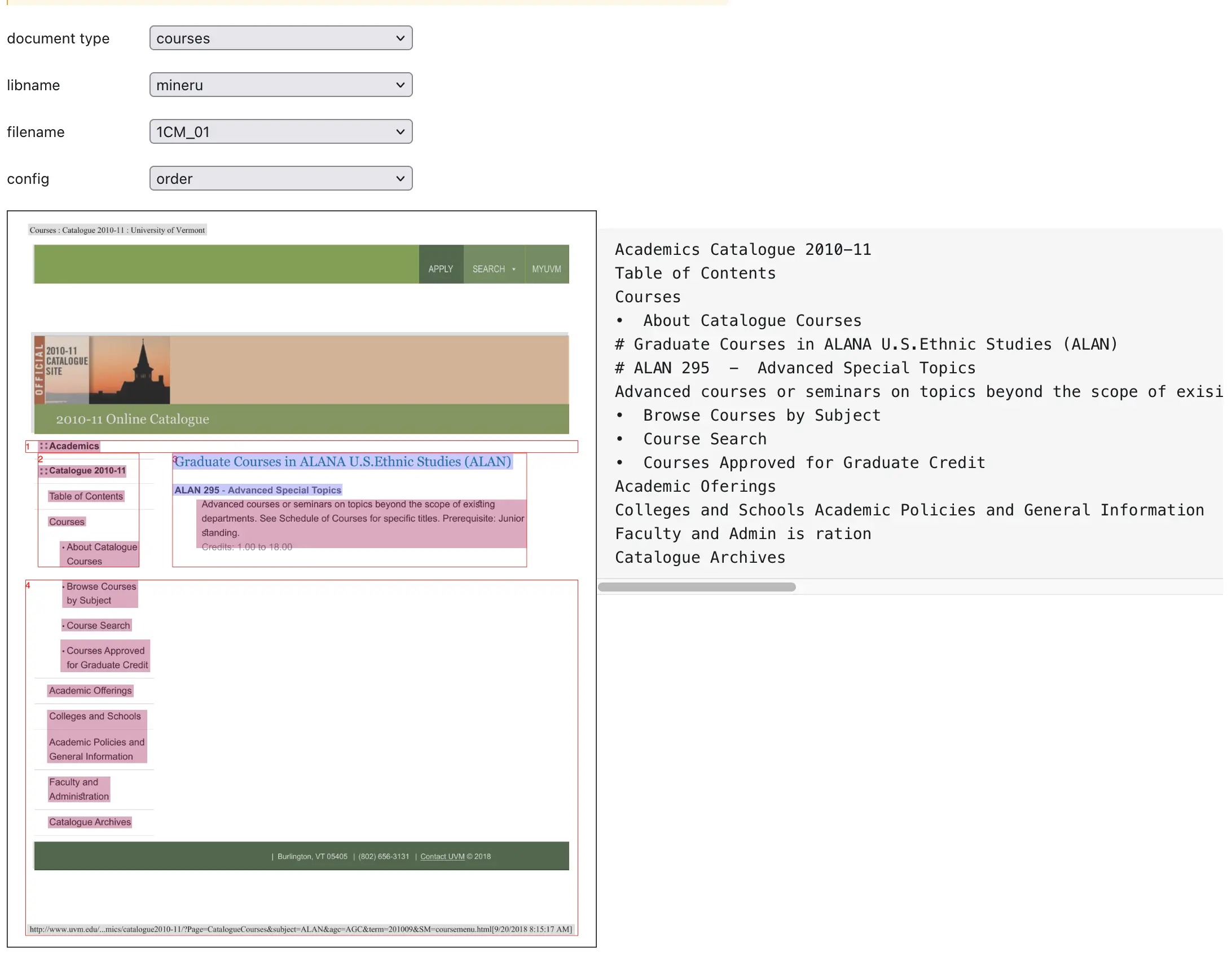
If you compare the two outputs above, you’ll notice that the second tool goes a step further; it removes boilerplate text. It’s a bold move, but I like it. In this case, I agree that I wouldn’t want that text included.
Overall, the data app is still in its early stages, but I already find it useful for quickly comparing the outputs of different tools on the challenging documents I work with.